SQL Server Data Compression
When people talk about data compression they are typically discussing archival – but Microsoft has used this very popular technology in a way that has managed to fall into the category of performance improvement. Here I am going to give you an example of how we can use compression to decrease disk latency, maximize memory efficiency and improve query response time all at the expense of a few CPU cycles.
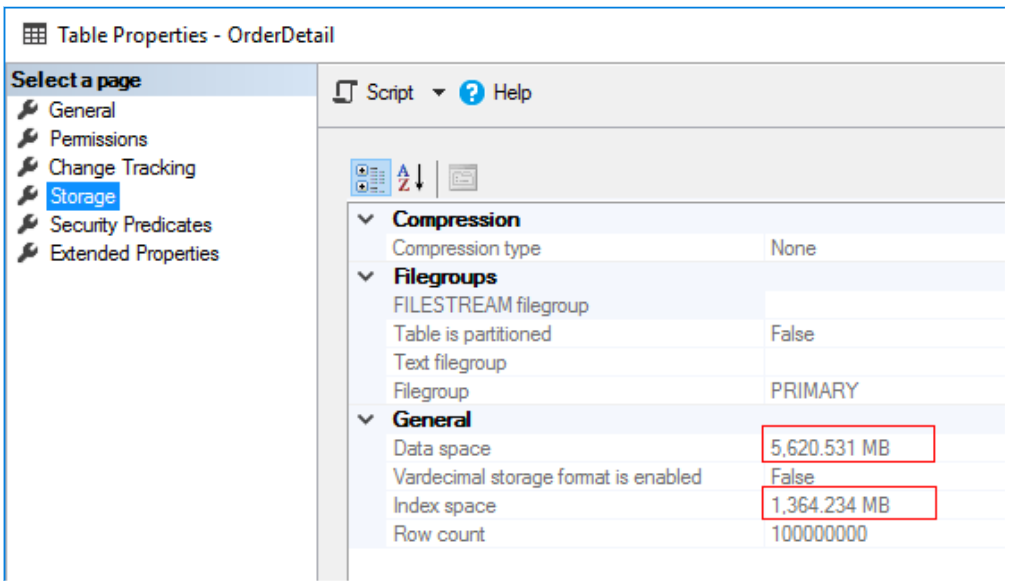
First, let’s discuss the testing parameters. We will be using a single table called [OrderDetail] in a database called [IndexTesting] with 100,000,000 (100 million) rows. The table has a clustered index on an integer identity column. There is also one non-clustered index on the [BuyerId] column which we will be using in the example queries. This table totals 6.8 GB in size. Before each test query, I will be freeing the SQL Server procedure cache and page cache using DBCC FreeProcCache and DropCleanBuffers respectively.
As you can see, 100,000,000 rows and about 7GB of storage:
Now that we have the parameters out of the way, lets discus one of SQL Servers most basic performance principles: reduce logical reads. Logical reads are basically just 8KB reads against any SQL object (such as a table) and those logical reads will preferably hit the SQL Server Page cache. However, when the data SQL Server needs in order to satisfy a request isn’t in the page cache, then it must go to the disk to gather the needed data. Going to disk is not what you want to happen – but hey, we do not all have infinite RAM in our servers.
Ok, lets run some queries on the uncompressed table called [OrderDetails].
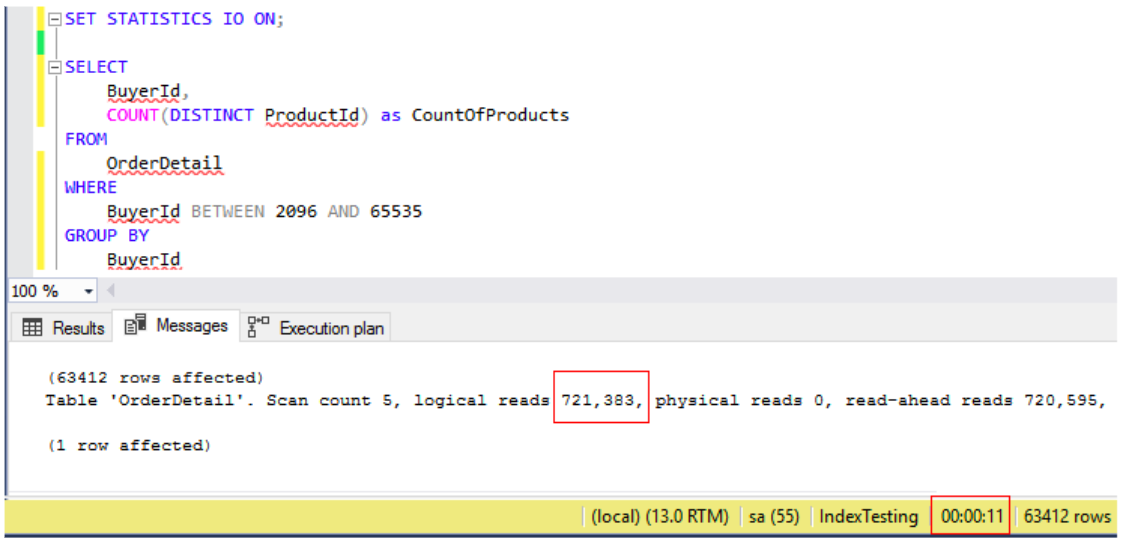
As you can see below, the query which I ran required 721,383 page reads and ran for 11 seconds.
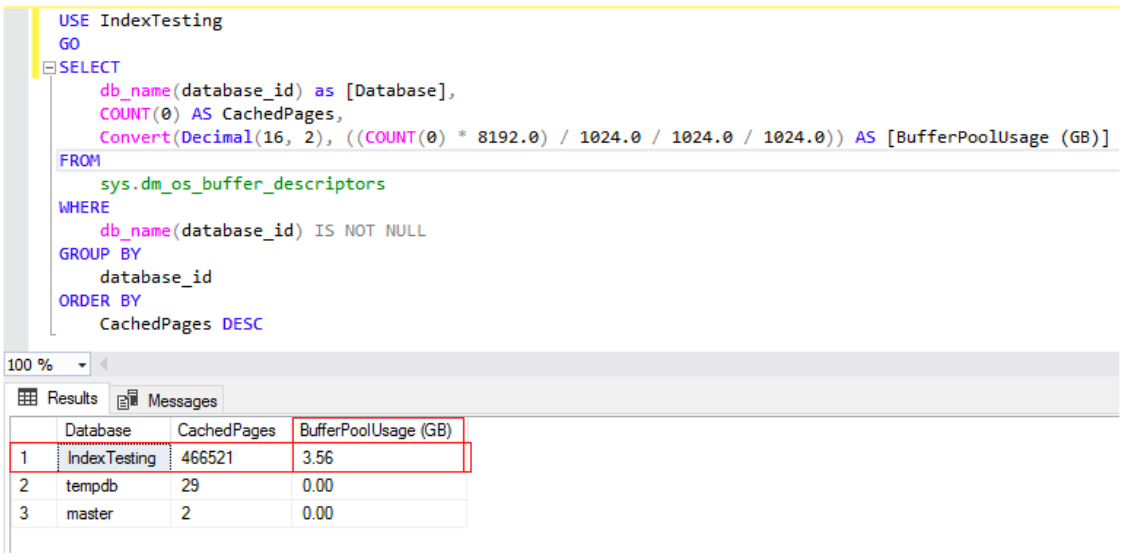
In addition to the number of logical reads, let’s look at the amount of page buffer being used by the [IndexTesting] database. Below you can see that after running the above SELECT query, SQL Server stored 3.56 GB of data in its cache. Yes, that translates to 3.56GB of used physical RAM – for one query! The only good news here is that the data for the query is now in RAM and any subsequent queries will not need to go to the disk – the downside is that this is an enormous amount of data and will likely not stay cached for long if there is any other workload.
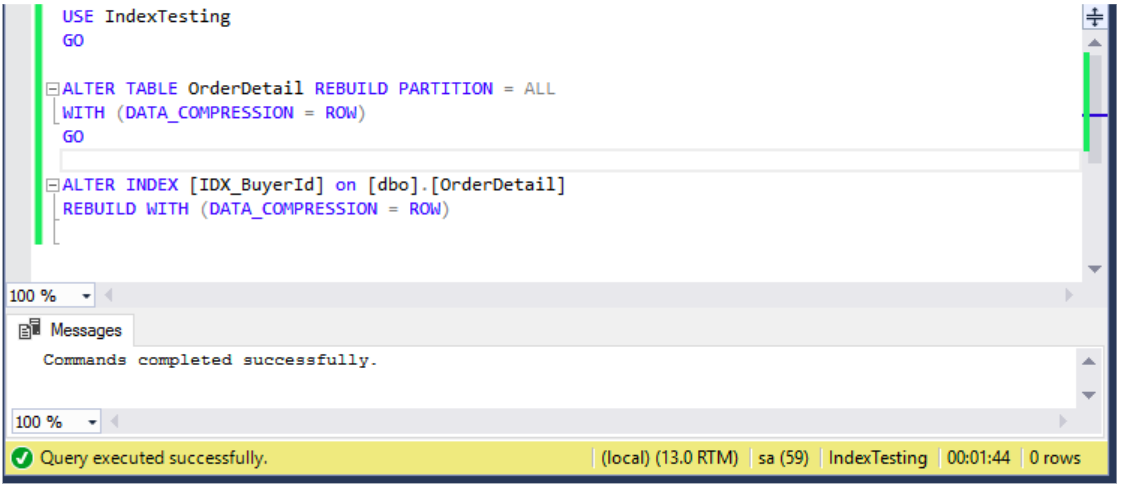
Let compress that table. Done! Here you can see that I am using PAGE compression and the operation took 1 minute 44 seconds. PAGE compression will generally result in better compression ratios than ROW compression but you shouldn’t just assume that. Test your data!
Here you can see that the table and index size has been significantly reduced. With PAGE compression, we achieved just over a 48% compression ratio.
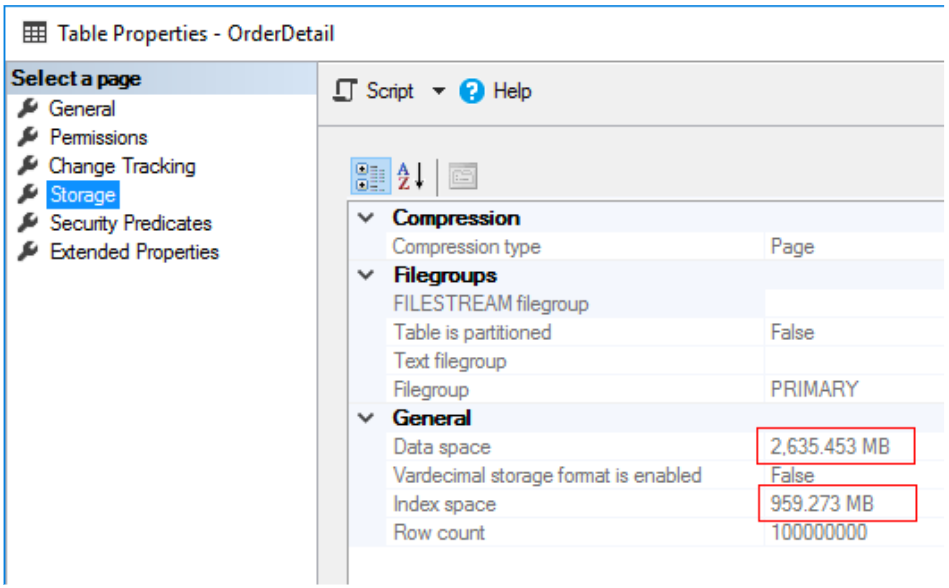
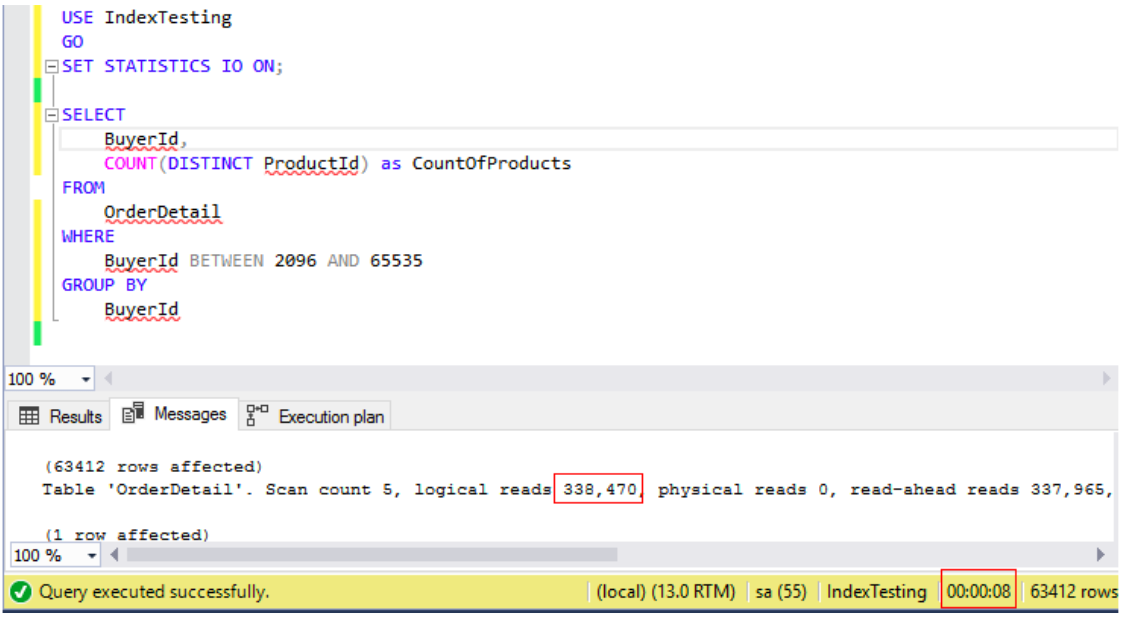
Now that the table is compressed, it is time to free the various caches and run the test scripts again. Keep in mind that this time SQL Server will be reading compressed data which it can’t natively use without first decompressing. This should be interesting!
The query ran for 8 seconds which is 3 seconds faster than uncompressed (yes, I ran these queries dozens of time, these figures were consistent). What’s more interesting than duration is that the logical reads have been cut in half! Think about it, if the data is stored on disk in a compressed state – then SQL Server needs to read less data from the disk – this also means that when inserting/updating a table that SQL Server will need to write less data to the disk as well. But it gets better…
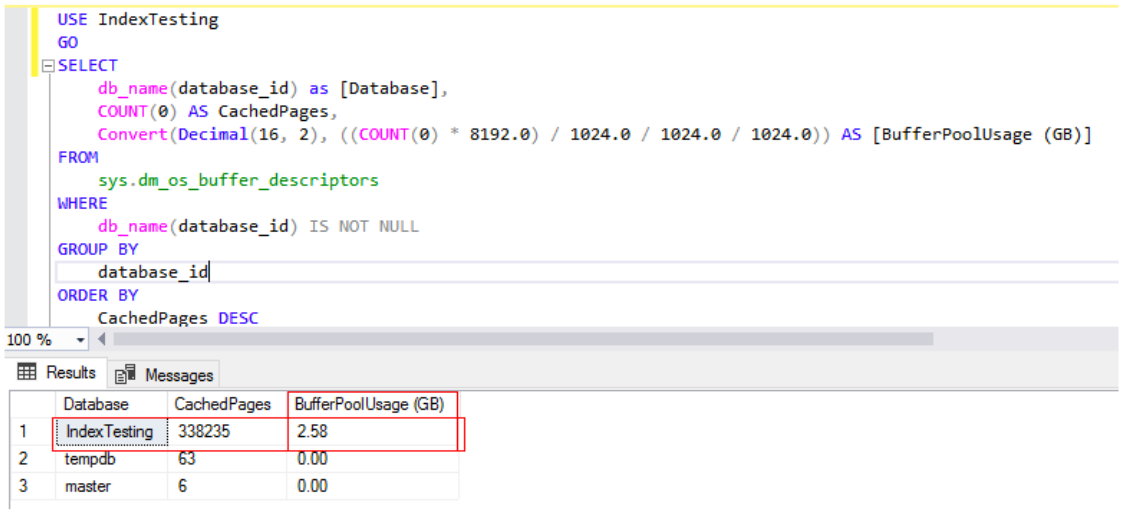
Below you can see that the buffer usage is roughly 30% smaller than it was after running the query on an uncompressed table. Yes! SQL Server also stores the data in the page pool in a compressed state. Your RAM is now giving you much more bang for your buck!
So, compression reduces disk reads, reduce disk writes, can make your queries faster, and allows you to use RAM more efficiently. What’s not to love?!
Well there are a few caveats.
- Compression is an Enterprise Edition feature, so you are going to incur some licensing costs if you are currently running something lower.
- Compression only operates on IN_ROW_DATA, so while intuitively is sounds like the perfect solution for those tables with a lot of text – it will not compress any data in LOB storage – so its not going to give you any relief with those VARCHAR(MAX) fields.
- Compression requires additional CPU cycles both when reading and when writing data – fortunately, the only significant overhead is on the compression – as opposed to decompression. Since most databases are 80-90 percent read – this shouldn’t be a problem for most applications.
if you want to do some further reading and really get down into the complexities of SQL Server data compression and partitions, see https://docs.microsoft.com/en-us/sql/relational-databases/data-compression/data-compression.